Combining Convolution and Attention Mechanisms
An overview of methods that effectively integrate their strengths
What is this article about?
This article explores 10 papers from machine learning that try to combine the inductive biases of convolution and attention. The focus will be more on understanding the core idea and intuition of these papers. Comparisons are given wherever available.
Prerequisites
I assume the reader thoroughly understands how various types of convolutions, and attention mechanisms work. If you are not familiar with them I highly recommend reading the following excellent blog posts:
Convolution: Convolutional Neural Networks(CS231n Stanford)
Attention: Transformers from scratch(by Peter Bloem)
1. Introduction
Convolutional Neural Networks(CNNs) and Transformers(attention mechanism) have both been extremely successful at computer vision tasks. However, their underlying inductive biases are different, thus their approach to learning representations over data is different.
CNNs have sparsely connected and shared parameters, due to which they pay more importance to the local structure, have relatively fewer parameters and can thus generalize well even when trained on smaller datasets(well "small" is relative, here ImageNet is "small", JFT 300M is "large"), however, they do not excel at learning global relationships and are less representative compared to Transformers.
Transformers, on the other hand, have dense connections, and the connection weights are dynamically adapted/computed depending on the input value, thus they find it easy to learn complex global relationships and are a lot more expressive compared to CNNs, however owing to this high representative power, they need to be trained on very large datasets(i.e JFT 300M ) to avoid overfitting issues.
Although the size of labeled open source classification datasets has been gradually increasing in computer vision, there are a huge number of applications (ex. digital pathology, climate, sports etc) that require niche data and thus have smaller datasets, plus, the sizes of detection and segmentation datasets are usually much smaller than classification owing to the increased complexity in labeling. Combining this with the fact that the inductive biases and thus the resulting pros/cons are complimentary for CNNs and Transformers. The question then becomes - "Can we unify these two approaches and get the best of both worlds?"
Let's dive in to find out!
2. Inductive biases and consequences
NOTE: If you are already familiar with inductive biases for Convolution and Attention layers, feel free to skip this section.
Whenever we design a machine learning system for any application, we decide on the model architecture based on our knowledge/pre-existing beliefs for that application. For example, sequential models like RNNs and LSTMs were designed for NLP because of the belief that sequential modeling is beneficial for NLP. Whenever we make a choice based on our belief about what is helpful, we induce a bias into the system, we call this an inductive bias.
To understand the effect of inductive biases we can view them through the lens of constrained optimization i.e. we reduce our search space to find the optimal function(model) under the constraint that it belongs to a particular family of functions(particular architecture). Thus depending on the inductive bias, we consequently end up with very different models. So we need to understand the consequences of inductive biases to be able to build better models.
Let us look at the workings of the Fully Connected, Convolutional and Self-Attention layers. Note that these will be simplified versions (i.e some low-level details may be omitted) which help us to focus more on the inductive biases while not being distracted by the details.
2.1. Fully Connected Layer

If the input and output at a layer $l$ are \(X_{4\times4}\) (i.e. a one-channel image-like input) and \(Y_{4\times4}\)(i.e. a one-channel image-like output). Then, if $l$ is a fully connected layer, the value of the pre-activation logit at node $i,j$ i.e \(y_{i,j}\) is given by:
$$y_{i,j}=\sum_{k=0}^{4}\sum_{l=0}^{4} w_{k,l}^{i,j}x_{k,l}$$
i.e. the logits at each node are a weighted sum of all the input activations \(x_{i,j}\). The weights used for computing the weighted sum for node \(y_{i,j}\) are part of the network parameters and are learned during training. This architecture is a perceptron based neural network layer and the weighted sum was inspired by how neurons in our brain communicate. This weighted sum approach to compute the logits is the inductive bias here.
The inductive biases are:
In general, for two nodes \(y_{a,b}\) and \(y_{c,d}\): \(W_{4\times4}^{a,b} \neq W_{4\times4}^{c,d}\)
i.e. for each node \(y_{i,j}\) a separate weight matrix \(W_{4\times4}^{i,j}\) is learned to compute the weighted sum.Each node \(y_{i,j}\) is connected to every single node in the previous layer
For each weight matrix \(W_{4\times4}^{i,j}\) the weights once learned are fixed and not dependent on the input.
Some consequences of the above inductive biases are:
As the weights for each node are different this means, for each node \(y_{i,j}\), we are computing/detecting a completely different feature/pattern in the input.
The network is not robust to any shifts in the inputs.
If you consider the weight/parameter \(w_{2,3}^{1,1}\) this is the weight that is connecting the output node \(y_{1,1}\) and the input node \(x_{2,3}\). While processing the weighted sum for the logit at \(y_{1,1}\): \(x_{2,3}\)is multiplied by \(w_{2,3}^{1,1}\) . The network learns the value for \(w_{2,3}^{1,1}\) such that it helps in computing the optimal weighted sum for this fea ture. Now, think about what happens when you give the model a new input \(X^{'}\)which is the original input $X$shifted to the left by 1 pixel. Now because of this shift, when computing the weighted sum for the same logit at \(y_{2,3}\): \(x_{2,4} \) (and not \(x_{2,3}\)) from $X$is multiplied by \(w_{2,3}^{1,1}\) which is not optimal. Thus if the input is shifted even by 1 pixel then this model will not be able to perform optimally i.e.
This architecture is suited for applications where the input nodes maintain a particular order. For example, if the data are the features [height, weight, age] of a person such that each data point has those feature values in the same order, then that would be a perfectly fine setting for using a fully connected layer.
In the case of images, depending on who captured the image there could be very big shifts in scale and location of the objects of interest within the image. Hence while this architecture may work for MNIST, it is not well suited for complex computer vision applications.
As each weight matrix is different there are a lot of parameters that the network must learn hence, overfitting could be a potential issue.
2.2. Convolution Layer

In the case of computer vision tasks, the relative location, scale of an object of interest within the image can be very different from one image to the other. Intuitively, we also know that a small local neighborhood is often sufficient to help identify key low-level visual features (e.g edges), which can then be aggregated further in the subsequent layers to identify high-level features (buildings).
Keeping the above belief in mind a sliding-window-based approach was suggested where we slide a small \(n\times n\) (n=3 in the above example) filter/kernel of learned weights \(W_{n\times n}\), over the image, and at each location, we compute the weighted sum from that particular \(n \times n\) local neighborhood. The idea is that the filter weights \(W_{n\times n}\) that are learned, correspond to a particular local visual feature (ex: edges, fur etc) and are learned such that the presence of those features gives a high weighted sum/logit values, i.e., in other words, detects the occurrence of these small features, and as we slide the same filter over the entire image, we are attempting multiple detections across various locations image, thus we will be able to detect the pattern irrespective of where it occurs in the image. This is the inductive bias in Convolutional Neural Networks.
If the input and output at a layer $l$ are \(X_{4\times4}\) (i.e. a one-channel image-like input) and \(Y_{4\times4}\)(i.e. a one-channel image-like output). Then, if $l$ is a convolutional layer, the value of the pre-activation logit at the node $i,j$ i.e. \(y_{i,j}\) is given by:
$$y_{i,j}=\sum_{k=-1}^{1}\sum_{l=-1}^{1} w_{k,l}^{i,j}x_{i+k,j+l}$$
i.e. the logits at a node \(y_{i,j}\) are a weighted sum of the input activations \(x_{i,j}\) lying within the local neighborhood of \(x_{i,j}\). Here the local neighborhood is chosen to be the \(3\times3 \) neighborhood centered around \(x_{i,j}\). Note that the same weights are used for computing the weighted sum at all nodes in $Y$ and are part of the network parameters that are learned during training. As illustrated in the above example, in this case, We follow this approach of sliding small filters because we believe this is well-suited for image-related tasks.
The inductive biases are:
For any two nodes \(y_{a,b}\) and \(y_{c,d}\) in $Y$: \(W_{4\times4}^{a,b} = W_{4\times4}^{c,d} = W_{4,4}\)
i.e. the same weights are shared across all nodesEach node \(y_{i,j}\) is sparsely connected i.e. only to a small neighborhood single node in the previous layer
For each weight matrix \(W_{4\times4}^{i,j}\) , the weights once learned are fixed and not dependent on the input.
Some consequences of the above inductive biases are:
Weight sharing across all nodes leads to translational equivariance. (if the input is shifted by a particular amount the output is also shifted by the same amount)
The bias towards local neighborhoods is often very helpful to vision tasks but it comes at a cost. It makes it difficult for the network to learn global dependencies. The only way CNNs learn global dependencies is when we stack a lot of CNN layers, the \(l^{th}\)layer aggregates some local neighborhood information/features and passes the output \(out^{l}\) to the layer \(l+1\) , which further aggregates local neighborhood information/features present in \(out^{l}\) to get \(out^{l+1}\). Thus the information/features in \(out^{l+1}\) correspond to a slightly larger local neighborhood than those at level $l$. Thus by stacking multiple convolutional layers on top of each other, we do get some global context but this is not necessarily the most efficient way as we might lose a lot of information.
Weight sharing and sparse connections reduce the number of parameters by a lot compared to a fully connected network. Hence overfitting is less of a concern
Note that the design of the convolution layer by itself is not robust to variations in scale, however since CNNs have a lot of layers plus the hierarchical stacking of these and the addition of max pooling etc give it some robustness to variations in scale.
2.3. Self-Attention Layer

It makes sense to want the network weights to depend on the input i.e. each input would be processed with a different set of weights that were calculated just for that input. This sort of inductive bias can enable the network to be robust to changes in the relative location of the object and also the relative scale of the objects within the image. Another way of looking at dynamic weight computation is that, depending on the input, we let the network decide which pixel locations it wants to focus more on (higher magnitude weights)and which locations it wants to ignore (low magnitude weight) i.e. we let the network decide where it wants to pay attention to depending on the given input! This is the inductive bias of various kinds of attention layers. In such layers instead of learning the weights directly, the network learns a weight computing function which can then be applied to any given input later to compute the weights for that input. The above figure illustrates a simplified attention layer for Q, K, and V attention where the logits for the node at \(i,j^{th}\) location are given by:
$$y_{i,j}=\sum_{k=0}^{4}\sum_{l=0}^{4} w_{k,l}^{i,j}f_{V}(x_{k,l})$$
$$w_{k,l}^{i,j} = Softmax(e^{i,j}{0,0},.....,e^{i,j}{4,4})$$
$$e_{k,l}^{i,j} = F_{attn}(f_{Q}(x_{i,j}),f_{K}(x_{k,l}))$$
$$F_{attn}(f_{Q}(x_{i,j}),f_{K}(x_{k,l}))= \frac{f_{Q}(x_{i,j})\cdot f_{K}(x_{k,l})^T}{\sqrt{d_{K}}}$$
The inductive biases are:
In general, for a given input X and two nodes \(y_{a,b}\) and \(y_{c,d}\): \(W_{4\times4,X}^{a,b} \neq W_{4\times4,X}^{c,d}\) and for two given inputs \(X_{1}, X_{2}\) \(W_{4\times4,X_{1}}^{a,b} \neq W_{4\times4,X_{2}}^{a,b}\)
i.e. for each node \(y_{i,j}\) a separate weight matrix \(W_{4\times4}^{i,j}\) is used to compute the weighted sum.Each node \(y_{i,j}\) is connected to every single node in the previous layer
Some consequences of the above inductive biases are:
As the weights for each node are dynamically computed based on the input, the network can choose to pay attention to different places based on the input. This makes it robust to changes in the relative location and scale of the objects within the image
There is nothing that makes the network pay more attention to local neighborhoods which has been proven to be important in vision tasks. This importance to local attention can be learned from the data but the model would need to be trained on a large amount of data to be able to learn this.
As the weights are densely connected and are distinct for each pixel there are a lot of parameters that the network must learn hence, overfitting could be a potential issue.
3. Merging the inductive biases
The existing methods that aim to merge the inductive bias of convolution and attention can be broadly classified into three categories:
Extrinsic Merging Approaches: These approaches perform some form of Convolution and Attention separately and then merge the outputs in various methods
Intrinsic Merging Approaches: These approaches merge the convolution and attention into one single operation
Extrinsic+Intrinsic Mergins Approaches: These approaches use an operator that combines convolution and attention into one single operator(intrinsic) and the on top of that applies regular convolution or attention separately(extrinsic)
Let us explore some techniques
3.1. Squeeze-and-Excitation Networks

CORE IDEA (This is an Extrinsic Merging Approach) [arxiv link]
In the Squeeze-and-Excitation Networks paper, the authors introduce the Squeeze-and-Excitatation(SE) blocks, to combine convolutions with attention. After applying the convolution filters, they focus on the channel dimension for applying attention, i.e. they propose to dynamically scale the activations in different channels in a convolutional volume within the SE block.
It is dynamic scaling because these attention weights are dynamically computed based on the input. The input \(X_{H\times W\times N_{in}}\) is first passed through a convolutional layer \(F_{conv}\)to get the output volume \(U_{ H\times W\times N_{out}}\)(this is the convolution-based output). \(U_{ H\times W\times N_{out}}\) is thne squeezed to obtain \(S_{1\times1\times N_{out}}\), this is done by applying global average pooling operation on \(U_{ H\times W\times N_{out}}\) i.e. we aggregate all the global information into one value! Then squeezed global information vector \(S_{1\times1\times N_{out}}\) is passed through an MLP followed by sigmoid activation to obtain the attention weights \(A_{1\times1\times N_{out}}\).
These weights are then used to scale \(U_{ H\times W\times N_{out}}\) i.e attenuate info from any unnecessary patterns/ channels (the network decides through attention which channels are unnecessary) depending on the input, to obtain the final output of the SE block: \(Y_{H\times W\times N_{out}}\) (this is the attention-based operation).
In this way we SE block mixes convolution and attention to learn local, global contexts and focuses on relevant patterns.
INTUITION AND ADDITIONAL THOUGHTS
1. What does "channel-based" attention do?
I believe we can think of it as follows:
In a convolutional layer, given a \(H\times W\times C\) output from layer $l$, each of the \(H\times W\)activations at a given channel $c$ correspond to the outputs of the \(c^{th}\) convolutional filter and indicate the presence(and strength)/absence of that particular pattern in different particular locations in the given input.
Now, say we are working on ImageNet classification. We have 1000 classes in our dataset, so it is fair to assume that each class will very likely need varying degrees of specialized filters for optimal performance. But what if some of these specialized filters while being very useful for a few classes, are detrimental to the remaining classes(for ex: if there are a bunch of filter's whose outputs have no signal for classifying the given object then their presence could just become noise and distracts the network from focusing on more useful patterns)?
Normally the model cannot handle this situation well and will probably have to trade off performance in some classes with that of other classes. However using the SE block and channel-based attention, the model is given the extra freedom to learn any required specialized filters it needs for the various classes and then for each given input, depending on the input, it can dynamically choose to focus only on the relevant filter outputs for the input. This could also enable the modle to learn multiple filters for the same feature but at different scales etc.
The authors also show that various filters(especially in the deeper layers) learn class-specific filters. Thus intuitively it makes a lot of sense to use channel-based attention!
2. What is the squeeze operation capturing?
The way the global information is aggregated at each channel in SE block is through global avg. pooling i.e. we are essentially taking the mean value of the entire \(H \times W\)section at each channel. As discussed above the information at each location in the \(H \times W\)channel is a number indicating the presence or absence of a particular visual pattern corresponding to the filter in the given input. So when we take the average of this globally across all spatial locations, the resulting \(A_{1\times1\times N_{out}}\)vector can think of as a distribution of the frequencies and strength of occurrences of the visual patterns corresponding to each of the \(N_{out}\) filters at that layer.
3. Why not Spatial Attention?
I was surprised that they only experimented with channel-based attention and did not experiment with spatial attention. The only reason I could think of this could be that they wanted to be as minimal a computational overhead as possible.
4. Are we losing too much information at the time of the squeeze operation?
They use the global avg. pooling operation for aggregating global information. One issue with this is that we lose all information regarding the spatial information regarding the occurrences of the patterns, it is not immediately clear if this information is even useful though. Squeezing to an \(r\times r\times C\) volume instead of \(1\times1\times C\) volume could retain some spatial information but at the expense of considerable increase in computation as this would increase the nodes by a factor of \(r^4\) in the MLP. So it is probably not worth it
COMPUTATIONAL AND MEMORY COST
The SE block is not very computation-heavy, and the only additional parameters introduced are those in the MLP for converting \(S_{1\times1\times C}\) to \(A_{1\times1\times C}\). So not a lot of overhead compared to similar typical CNNs
COMPARISON
This was the SOTA and won the IMAGENET challenge when this was released
3.2. Convolutional Block Attention Module

NOTE: There is another paper "BAM: Bottle Neck Attention Module" [arxiv link], by the same authors, which I feel at a high level is very similar to this and hence will not be covered here, feel free to go through it if you are interested!
CORE IDEA (This is an Extrinsic Merging Approach) [arxiv link]
In The Convolutional Block Attention Module(CBAM) paper, the authors propose an extension to the SE block, by incorporating spatial attention in addition to channel attention, at a high level it similarly combines convolution and attention as the SE block does but with some modifications:
1. (Modified) Channel Attention:
In SE blocks the squeeze operation consisted of performing global avg. pooling to get one \(S_{1\times1\times C}\) volume. CBAM proposes that in addition to avg. pooling we perform another squeeze operation (in parallel) by global max pooling to get two squeezed volumes: \(S_{1\times1\times C}^{avg. pool}\)and \(S_{1\times1\times C}^{max pool}\). These are then passed through a shared MLP to obtain two corresponsing outputs which are then added and passed through sigmoid activation to get the final channel attention weights. The authors show empirically that using 2 squeezed vectors from avg. pooling and max pooling is better than using just one.
2. Spatial attention:
In addition to the channel based attention they also propose performing spatial attention. The spatial attention weights are computed from and applied on \(Y_{H\times W\times C}^{'}\) i.e the output after channel attention based refinement. First \(S_{H\times W}^{avg.pool} \) and \(S_{H\times W}^{max.pool} \) are obtained by performing global avg.pooling and global max pooling on \(U_{ H\times W\times N_{out}}\). These are then concatenated across the channel axis and passed through a \(7\times7\) convolution filter followed by a sigmoid activation to obtain the spatial attention weights. \(Y_{H\times W\times C}^{'}\) is then scaled using the spatial attention to get the final output \(Y_{H\times W\times C}\). The authors show empirically that the addition of spatial attention improves results. The authors also experimented with computing channel and spatial attention in parallel but empirically found this configuraiton to work best.
INTUITION AND ADDITIONAL THOUGHTS
1. What Additional information does Max Pooling based squeeze operation give?
I think we capture the following additional information through max pooling - Global avg. pooling will give information regarding the frequency of occurrences of patterns but not the strength of the filter responses as averaging will dilute this information, Max pooling on the other hand will capture the strength of the strongest occurrence of this pattern and thus will have the information about the strength of the pattern match. So this is the extra information that empirically is helpful for the model. It makes a lot more intuitive sense in spatial attention computation as we will discuss below.
2. Why local Spatial Attention?
While it makes sense to use spatial attention, it is to be noted that we are using local neighborhoods here to compute spatial attention. We have [ \(S_{H\times W}^{avg.pool} \) , \(S_{H\times W}^{max.pool} \) ] stacked across the channel dim. max pool component will give information on what is the most prominent feature in that location(which is very useful information) and avg. pool component will give information on what is the average strength of the presence of all the useful patterns at this location(as this is after we scale with channel attention weights). Depending only on this local information the network is learning attention weights at each location to scale the information at that location. So it is potentially attenuating some features which might not be relevant in the presence of other features around that location. If it had access to global information across \(H\times W\) at this stage then I feel it would have been able to learn much better spatial attention features but that would be a lot more expensive computationally.
COMPUTATIONAL AND MEMORY COST
Considering the squeeze operation and the only one \(7\times7\) convolution, the additional computational cost is not too high. So not a lot of overhead compared to similar typical CNNs
COMPARISON
This improves the performance over Squeeze and Excitation Networks
3.3. Relative Self-Attention

CORE IDEA (This is an Intrinsic Merging Approach) [arxiv link]
The self-attention mechanism in transformers is permutation invariant. This is highly undesirable, hence global positional encodings/embeddings were proposed in the original transformer paper to break the permutation invariance. However, in applications like computer vision(NLP as well), it is desirable to have translational equivariance. Global positional encodings cannot help with this and are in fact detrimental to this.
CNNs have this property due to their parameter-sharing approach. Due to this parameter sharing, if any two pairs of pixels \((p_{1}^a,p_{2}^a)\) and \((p_{1}^b,p_{2}^b)\) have the same relative position between them (ex: \(p_{2}^a\) is 3 pixels to the right, 4 pixels down from \(p_{1}^a\) and similarly \(p_{2}^b\) is 3 pixels to the right, 4 pixels down from \(p_{1}^b\)), then \(p_{2}^a\) will affect \(p_{1}^a\) in exactly the same way as \(p_{2}^b\) will affect \(p_{1}^b\).
Inspired by this the authors propose modifying the attention mechanism by introducing new parameters into it which are shared based on similarity in relative position, regardless of their absolute location. We will focus only on one particular modification which was found to be the most effective and further was used in later literature relevant to this article.
Typically for computing the output \(Y_{i}\) at position, the logit for paying attention to the $value$ vectors at position $j$, is given by:
$$e_{ij}=\frac{(X_{i}^{q})^{T}}{\sqrt d_{k}} (X_{j}^k)$$
The above form of attention has no parameter that is dependant on the relative positons of $i,j$ , all parameters depend on absolute $i,j$. To introduce a translational equivariance component to this the authors propose adding relational positional embeddings to the keys, such that the same embedding will be the same for all $i,j$ for which \(j-i\) is the same. The modified form is given by:
$$e_{ij}=\frac{(X_{i}^{q})^{T}}{\sqrt d_{k}} (X_{j}^k + r_{j-i})$$
As you can see \(r_{j-i}\)is the relative position embedding that is added to the key values while computign the attention logit. All $i,j$ pairs which have the same \(j-i\) value will use the same parameter \(r_{j-i}\), i.e. \(e_{10,15}; e_{20,25}\) both use
\(r_{5}\) (Note that e_{15,10} will be using \(r_{-5}\) and not \(r_5\)). This will make a small part of the whole computation, translational equivariant, which is still a step in the direction we believe to be helpful. If the length of the input sequence for the model is N, then, there will \(2N-2\) different possible \(r_{j-i}\)'s i.e at one extreme you will have \(i=1,j=N\)i.e. \(j-i=N-1\) and at the other extreme \(i=N, j=1\) i.e. \(j-1 = 1-N\), thus total possibilities for \(j-1\) are \((N-1) - (1-N)= 2N-2\). Each of them will have the same dimesnion \(d_{k}\) as the keys. Thus there will be \(2N-2\)new parameters for positional embeddings.
INTUITION AND ADDITIONAL THOUGHTS
Intuitively adding the relative position embeddings can be thought of as adding a global convolution filter and the resulting output to the pre-softmax attention weights. Thus it intuitively combines both convolution and attention.
The authors do not experiment with the approach in computer vision, later papers expand this idea and use it in computer vision.
3.4. Attention Augmented Convolutional Networks

CORE IDEA (This is an Extrinsic + Intrinsic Merging Approach) [arxiv link]
The core idea here is very simple, the authors propose "Attention Augmented Convolution" blocks that integrate the inductive biases of convolution and attention in two places:
As shown in the above illustration the blocks perform both self-attention as well as a convolution over the input in parallel, these two outputs are then concatenated to obtain the attention-augmented convolution output.
The attention mechanism used here is the 2D relative self-attention which is an extension of the 1 D Relative Self-Attention we discussed above. Thus the attention mechanism itself also introduces some of the convolutions inductive biases like some parameters exhibiting translational equivariance. 2D relative self-attention logits are computed as follows:
$$e_{ij}=\frac{(X_{i}^{q})^{T}}{\sqrt d_{k}} (X_{j}^k + r_{j_{x}-i_{x}}^W+r_{j_{y}-i_{y}}^H)$$
If the size of the input volume is \(H \times W\times C\), each relative positional embedding will have c parameters and there will be different relative positional embeddings and thus \((2(H+W)-2)C\) parameters.
INTUITION AND ADDITIONAL THOUGHTS
Since the concatenated output has channels from both the conv layers as well as attention layers, the downstream layers will have access to both local and global features which should enable the model to learn better features.
COMPUTATIONAL AND MEMORY COST
This does have high memory costs compared to normal attention mechanisms when implemented normally, so they optimize the implementation to make it more efficient(please refer to the paper for more details on this). In addition, they start adding these layers from the end of the network as the spatial dimension is the smallest there
COMPARISON
Attention Augmented convolutional networks improve upon CBAM
3.5. End-to-End Object Detection with Transformers

CORE IDEA (This is an Extrinsic Merging Approach) [arxiv link]
In this paper, the authors introduce the DEtection TRansformer(DETR) framework for object detection. This framework integrates the strengths of convolution and attention straightforwardly.
Typically the object detection frameworks like 'Faster RCNN' have a convolutional feature-extractor(CNN backbone), Region proposal prediction head, bounding box, and class prediction heads. The job of the CNN backbone is to extract all the relevant visual features from the input image. The Region proposal head uses the information from the earlier layers of CNN backbone to predict the potential salient regions of the image (i.e regions that potentially have objects in them) called ROI (region of interest). The classification and bounding box prediction heads then operate exclusively on these ROIs and use the CNN extracted features from those regions to make bounding box, class predictions.
DETR framework too, has a convolutional feature extractor (CNN backbone), class and bounding box prediction heads, however, instead of the region proposal prediction head DETR has an encoder-decoder Transformer stage. A typical CNN like ResNET50 etc is used as the CNN backbone to extract the visual features, then the encoder-decoder transformer blocks take the rich visual features computed by the CNN backbone and apply attention to the salient regions of the entire image and use the corresponding features from the CNN backbone to extract more complex and global patterns that the CNN backbone could not extract by itself, which are then used by the bounding box, class prediction heads (these are simple feed-forward networks) to make the class, bounding box predictions. Thus DETR framework fuses the strength of CNNs with Transformers in this way.
Note that DETR has another key component - the bipartite loss function to enable object detection using this framework. However, since it is not relevant to the topic of the article I will leave not be discussing it here. In case you want to use this framework you can find all the details in the DETR paper linked above.
INTUITION AND ADDITIONAL THOUGHTS
This is a generalization of the Faster RCNN Framework
This can be thought of as a generalization of the Faster RCNN framework. In the Faster RCNN framework, the region proposal network makes ROI predictions. After this step all the subsequent stages of the network only focus on the prediction ROIs, this can be thought of as a form of attention - Hard Attention. In DETR instead of fixing an ROI we give the entire convolutional volume to the Transformer mechanism and leave it to the network to figure out where it wants to focus and the weight for each pixel. I.e it is a soft attention mechanism. Thus it makes perfect sense that this approach performs better than RCNN models because some information may be lost when we apply hard attention (RCNN).
COMPUTATION AND MEMORY COST
Compared to the Faster RCNN framework, DETR has lower frames per second (FPS) rate despite having fewer parameters.
COMPARISON
Outperforms Faster RCNN
3.6. CvT: Introducing Convolutions to Vision Transformers
CORE IDEA (This is an Intrinsic Merging Approach) [arxiv link]
CvT stands for convolution vision transformer. In this paper, as the name suggests the authors combine convolution and attention mechanisms by introducing the convolution operation into the transformer block at 2 places.
1. Convolutional Token Embedding at the beginning of each stage
At the beginning of each stage, there is a convolution token embedding layer. This is a regular convolution layer that is run with stride $s$. This is applied to the input to this layer (in the interior layers the \(H^{in}W^{in}\times C^{in} \) shaped sequence input is first reshaped into the appropriate \(H^{in}\times\ W^{in}\times C^{in}\) shape). The output size, \(H^{out}\times\ W^{out}\times C^{out}\) of the convolution token embedding is defined based on the stride $s$ and number of filters \(C^{out}\). The use of convolution token embedding ensures that important local representations over the attention-based outputs are learned easily, it also achieves spatial down-sampling while increasing the number of feature maps(channel dimension) similar to CNNs
2. Convolutional Projections for Attention
Normal transformers use 3 different linear projections for the Q, K, and V embeddings. In the case of CvT, the authors propose replacing the 3 different linear projections with 3 different depthwise convolutions. This potentially enables better projection into the Q, K, and V embeddings as Q, K and V embeddings at a given location now depend on the local neighborhood of that location and this usually works well based on what we know from CNNs.
Through ablation studies the authors empirically prove the effectiveness of the proposed convolutional token embeddings and convolutional projections in improving model performance (when used individually and also when combined). Further, the authors also show that CvT does not need to use positional encodings/embeddings and in fact not using them increases the performance of CvT. This shows that the convolutions introduced are helping the network retain information about relative spatial locations
INTUITION AND ADDITIONAL THOUGHTS
The convolutional filters potentially give more informative inputs to the attention heads
The convolutional token embedding layer is applied to the output from the previous stage, this output essentially has the information on global features computed based on self-attention. Applying local filters like a convolution over this potentially lets the network learn the local patterns w.r.t the presence of global features learned through self-attention, this also allows the network to further amplify important or attenuate duplicate information.
The use of convolutional filters for projection into Q,K,V makes a lot of sense because typically when creating these projections, each item in the sequence is processed independently however this completely ignores any valuable local information. We can easily overcome this issue by using convolutional filters at this stage that take into account local neighborhoods. The fact that CvT performs better without positional embeddings possibly means the local information is helpful and is also sufficient to retain any position-related information
In the paper, the strided convolution was proposed only for K, V projections and not for Q projections, for convolutional output volumes it is usually common to have similar information in adjacent locations and that is why strided convolution was proposed for K, V but the same logic would apply to Q too but I cannot think of a reason as to why that was not done. It might be an interesting thing to try.
COMPUTATION AND MEMORY COSTS
Due to the reduction in resolution through strided convolutional token embeddings and strided convolutional projections this is generally better than typical $ViTs$ in terms of computation resources
COMPARISON
Performs better than $ViT, DeiT,PVT$
3.7. CoAtNet: Marrying Convolution and Attention for All Data Sizes
CORE IDEA (This is an Intrinsic Merging Approach) [arxiv link]
In this paper, the authors point out how transformers have high model capacity(achieve high accuracy on training data) but can often overfit if the dataset size is small, while on the other hand, CNNs are great at generalization and do not overfit even on smaller datasets but they have typically lower model capacity. The authors want to combine convolution and attention to understand what network structure works best to create models that have both-1) good generalization and 2) Model capacity for small as well as large datasets. They focus on two key areas:
1. A systematic approach to integrating convolution and attention
While earlier works focused on general convolutions, in this paper the authors show that depthwise separable convolutions are more amenable to be integrated into the attention mechanism. Depthwise convolution operation can be mathematically expressed as
$$y_{i} = \sum_{j\in N(i)} w_{i-j} \bigodot x_{j}$$
where \(\bigodot\) is the element-wise product (Hadamard product), \(y_{i}\)is the \(R^{C}\) output at pixel $i$ , \(x_{j}\) is the \(R^{C}\)input at the pixel $j$, $N(i)$ is the local neighborhood around the pixel $i$ as defined by the convolution kernels. Since this is a depthwise convolution and the input has $C$ channels. There will have to be '$C$' - \(k\times k\) 2 dimensionsal convolutional filters. Although these are C separate conv filters, we can string together the filter parameter that is at a relative position of \(i-j\) from the center of each of the C filters to get the \(R^C\)dimensional vector \(w_{i-j} \) that is used above.
Self attention on the other hand would have the following expression:
$$y_{j}=\sum_{j \in \mathcal{G}(i)} \underbrace{\frac{\exp (x_{i}^Tx_{j})}{\sum_{k\in \mathcal{G}(i)} \exp (x_{i}^Tx_{k})}}{A{i,j}} x{j}$$
$$i.e. \hspace{1cm} y_{j}=\sum_{j \in \mathcal{G}(i)} A_{i,j}x_{j}$$
Comparing both the equations we see that they have a similar form i.e both are a weighted average over input but they have the following differences:
1. \(w_{i-j}\) are local, static and have translational equivariance
2. \(A_{i,j}\) are global, adaptive (change with input), and do not have translational equivariance
To combine these two, the authors propose to sum the attention matrix to a global static convolution matrix before the softmax normalization:
$$y_{j}=\sum_{j \in \mathcal{G}(i)} \underbrace{\frac{\exp (x_{i}^Tx_{j} + w_{i-k})}{\sum_{k\in \mathcal{G}(i)} \exp (x_{i}^Tx_{k}+ w_{i-k})}}{relA{i,j}} x{j}$$
Note that \(w_{i-j}\) is a scalar here(\(i.e. w_{i-j}\notin R^C\)). This ensures minimal additional cost during training! In \(relA_{i,j}\)the attention-based dot product part is adaptive to input and does not have translational equivariance whereas the static convolution kernel part is static and has translational equivariance, so depending on the relative magnitudes of these both the network can choose the optimal balance between these two biases.
2. Optimal stacking of pure convolutional layers and the hybrid layers:
After designing the above approach for merging convolution into the attention mechanism, the authors experiment with the optimal way to stack these hybrid attention layers in the network. To keep the comparison fair, in all their experiments they design networks containing 5 stages \(S_0,S_1,S_2,S_3,S_4\) just like the typical CNNs. Each stage could essentially be made of convolutional layers or Transformer layers with relative attention (i.e with the convolution bias merged into the attention). Note that in all their experiments \(S_0\)is the convolutional stem in all experiments, \(S_1\)is also convolutional in all experiments and is made up of MBConv with SE blocks. The reason for not having attention in these stages is because these initial layers have high spatial resolution and it is not practically feasible to apply attention due to its quadratic complexity. So the authors experimented with the following configurations:
1. C-C-C-C-C
2. C-C-C-C-T
3. C-C-C-T-T
4. C-C-T-T-T
5. \(ViT_{Rel}\) (Same structure as the $ViT$ but with relative attention designed above)
To evaluate which configuration was best overall the authors focused on two criteria
1. Generalization capability: On ImageNet 1k which is a relatively smaller dataset, overfitting is always a concern, the more the model overfits the more is the gap between training loss and validation metrics. Intuitively if two models have the same training loss then, of the two models the model with a higher validation metric is better. Based on this criteria the authors determine the following ranking:
C-C-C-C-C ≈ C-C-C-C-T ≥ C-C-C-T-T > C-C-T-T-T ≫ \(ViT_{Rel}\)
As expected, the more convolutional stages better the generalization capability. This intuitively makes sense because conv blocks have a much stronger inductive bias and much fewer parameters compared to the transformer block. However, generalization capability only captures how consistent the model is across datasets which is not sufficient to determine an overall best model, it is also important to look at the absolute performance in addition to consistency.
2. Model capacity: In larger datasets like JFT, we can worry less about overfitting and focus on which architecture can fit the data better i.e. achieve higher accuracy. The model performance on both training and validation data gives us a sense of model capacity. Based on this criteria the authors determine the following ranking:
C-C-C-T-T ≈ C-C-T-T-T > \(ViT_{Rel}\) > C-C-C-C-T > C-C-C-C-C
Except for the ranking of \(ViT_{Rel}\), the ranking of all other models makes intuitive sense. We would exepct that the more the transformer layers the better the freedom to learn more complex realtions and hence the achieve higher the model accuracy. So we would expect \(ViT_{Rel}\) to have the highest accuracy but it does not seem to be the case. The authors hypothesize that the lower ranking of \(ViT_{Rel}\) is due to the loss of local information in \(ViT_{Rel}\) at the initial stages itself due to the aggressive stride/downsizing it does to create 16x16 patches.
It is also interesting to note the C-C-T-T and C-T-T-T seem to have the same capacity which seems to indicate that just increasing the transformers doesn't mean higher performance and there is a point where the model capacity saturates. This also shows that the transformers are better suited for later stages and convolutions are better suited for earlier stages.
Upon further conducting transfer learning experiments (from JFT to ImagNet)
C-C-C-T-T performed better than C-C-T-T-T hence they recommend C-C-C-T-T as the overall best configuration.
INTUITION AND ADDITIONAL THOUGHTS
Relative attention is a "Soft Lever"
In all the previous methods there was some kind of "hard lever" to combine convolution and attention - i.e we have a rigid combination of CNN and Attention layers. However, in this approach, it is a "soft lever" - the relative attention itself has both the static global convolutional filter and the global self-attention and it is up to the network to learn the relative magnitude of weights and it can decide if it wants to give a higher weightage to convolution aspect or the attention aspect.
COMPUTATIONAL AND MEMORY COST
It is less demanding compared to $ViT$ and more demanding compared to CNNs
COMPARISON
Outperforms CvT
3.8. Early Convolutions help Transformers see better
CORE IDEA (This is an Extrinsic Merging Approach) [arxiv link]
$ViTs$ have emerged as a promising new architecture for computer vision applications however they have substandard optimizability i.e. very unstable to changes in some of the hyperparameters like optimization technique(AdamW vs SGD). In this paper, the authors focus on improving this optimizability(not just the performance). Note that this is not directly related to merging convolution and attention, however the solution proposed by the authors, does benefit from the inductive biases of convolution and attention. Thus I felt it is relevant to this article.
The standard $ViT$ uses a "patchify stem", which is a \(p\times p\) convolution with stride $p $ . In the $ViT$ paper \(p=16\). The purpose of this stage is to create embeddings from the input image to feed to the transformer blocks in the network. The high stride was probably chosen keeping the quadratic complexity of attention in mind. The multiple transformer blocks would then apply self-attention to learn strong representations of the input. This was the standard $ViT$ framework proposed by the $ViT$ paper. However, this setup was found to have very poor optimizability i.e. standard $ViT$ setup is very sensitive to the optimizer being used (AdamW vs SGD), the hyperparameters used (training length etc, depth etc).
The patchify stem has a large filter size and very aggressive stride/downsampling. This is very different from the filters used in convolutional networks which usually have a small stride and filter size. Note that as this is the first stage of the network, if a lot of information is lost/ the input is processed sub-optimally then it becomes a bottleneck and the rest of the network despite its strong representaitonal power cannot really do much due to the loss of informaiton in the early stages. The authors hypothesize that the patchy stem is the source behind the substandard optimizabiity of the standard $ViT$.
They propose very minimal changes to fix this. These changes are inspired by what works in the traditional CNNs. Instead of one aggressive strided convolution filter they propose a Convolutional stem made of 5 layers of \(3\times 3\), stride 2 convolutions that gradually bring the input the same dimensions as the "patchify" stem in the original $ViT$. These outputs are then fed to the transformer blocks as before with the only difference being, to account for the additional convolution parameters that were added the authors remove one transformer block to maintain roughly, the same number of parameters, runtime etc. The authors refer to the original ViT which uses the "patchify" stem as \(ViT_{P}\) and the $ViT$ which uses convolution stem as \(ViT_{C}\) .
Note that the modifications for \(ViT_{P}\) is still only 5 convolution layers and the bulk of the computation still happens in the transformer section and is identical between \(ViT_{P}\) and \(ViT_{C}\). Despite this seemingly small, the optimizability increases drastically after this. \(ViT_{C}\) was found to have better:
1. Training length stability (faster convergence)
2. Optimizer stability (works well with adamW and SGD )
3. Hyperparameter stability(better stability for important hyper parame like lr and
weight decay)
4. Peak performance(beats sota CNN's on ImageNet dataset!)
Thus this empirically proves that the "patchify" stem is substandard and it is a highly benificial design choice to use the convolutional stem for the $ViT$ instead of the "patchify" stem
INTUITION AND ADDITIONAL THOUGHTS
The stem part of the network is essentially like a preprocessing stage where the image input is turned into a form that is suitable to be processed by the transformer blocks. If the preprocessing at this stage is substandard or loses crucial information then the transformer blocks get badly processed inputs and cannot perform well.
Given the big stride, it is very likely that the aggressive downsampling and large filter size leads to loss of information, and substandard embeddings compared to the convolutional stem where the input is gradually processed using multiple overlapping small local windows to aggregate rich local and hierarchical features at multiple scales before being presented as inputs to the transformer stage. The convolutional stem simply is capable of learning better embeddings and thus give better inputs to the transformer blocks thus the overall network has better optimizability and performance!
In short, the quality of inputs to transformer blocks is a lot better when using the convolutional stem instead of the "patchify" stem.
COMPUTATIONAL AND MEMORY COST
Computational and memory costs are similar to $ViT$ with no considerable overheads introduced.
COMPARISON
Performs better than $ViT$
3.9. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
CORE IDEA (This is an Intrinsic Merging Approach) [arxiv link]
Swin Transformer stands for Shifted Window Transformer. In this paper, the authors try to combine attention and convolution to make transformers that work better for computer vision applications. They propose modifying the typical multi-head self-attention(MSA) which has a global receptive field into a Shifted Window multi-head self-attention (SW MSA) which has only a local receptive field i.e. a windowed version of attention. In the paper, they suggest a \(M\times M\) local window, with M=4. There are four key details:
1. These windows are all Non-Overlapping
We create the windows(each window is \(M\times M\)) such that they are non-overlaping, this is achieved by creating a uniform grid where each grid cell is the \(M\times M\) window. (You can also think of this as \(M\times M\) sliding window with stride M, hence no overlap between the windows)
2. The complexity of attention is linear to the size of the image
Self-Attention is applied within each of the windows separately. So the complexity of attention is proportional to \(M^2 \times\)(number of windows), but the number of windows is \(\frac{H}{M} \times \frac{W}{M}\), whcih means the complexity of attention is linear in the size of the input image. This linear complexity is achieved because of the local attention and the fact that the windows are nonoverlapping.
3. Patches/Windows are "merged"(after downsampling) at various depths to learn hierarchical features
The entire architecture is made up of multiple stages and each stage has multiple transformer blocks within it. At the beginning of each stage, there is a patch merging layer that receives the \(H\times W\times C\) input from previous layer and applies a linear layer locally to convert each grid-like \(2\times2\times C\) spatial patch from input into a\(1\times1\times2C\) spatial volume i.e. the \(H\times W\times C\) volume is converted to \(\frac{H}{2}\times\ \frac{W}{2}\times2C\) , i.e the patch merging layer functions a bit similarly to max pooling.
So after this operation, each of the new \(M\times M\)patches now contains information from 4 adjacent \(M\times M\) patches from the previous stage. This helps the network learn hierarchical information.
4. Successive Transformer blocks(within each stage) have a Shifted Window partitioning
Since the window-based attention mechanism is local within each window and does not have connections between different windows, this could potentially limit the representative power. Hence, to overcome this, the authors propose a shifted window partitioning system that alternates between 2 configurations for successive transformer blocks. One configuration is the default grid configuration, while the other is the default configuration shifted by \((\frac{M}{2},\frac{M}{2}) \) pixels. Alternating transformer blocks in the architecture have alternating configurations!
Note that the attention mechanism they use is a variant of relative attention.
INTUITION AND ADDITIONAL THOUGHTS
SWIN transformer is essentially very similar to a CNN, it is similar in structure to a CNN with \(M\times M\) kernel and stride $M$ but the key difference is that while the filter weights are static for a CNN filter, here the weights are all dynamically adapted(attention mechanism) based on the input image. The patch merging between each stage in the network functions similarly to a Max Pooling layer.
COMPUTATIONAL AND MEMORY COST
It is much more efficient compared to regular $ViT$ and slightly worse compared to CNNs
COMPARISON
Performs better than $ViT, DeiT$
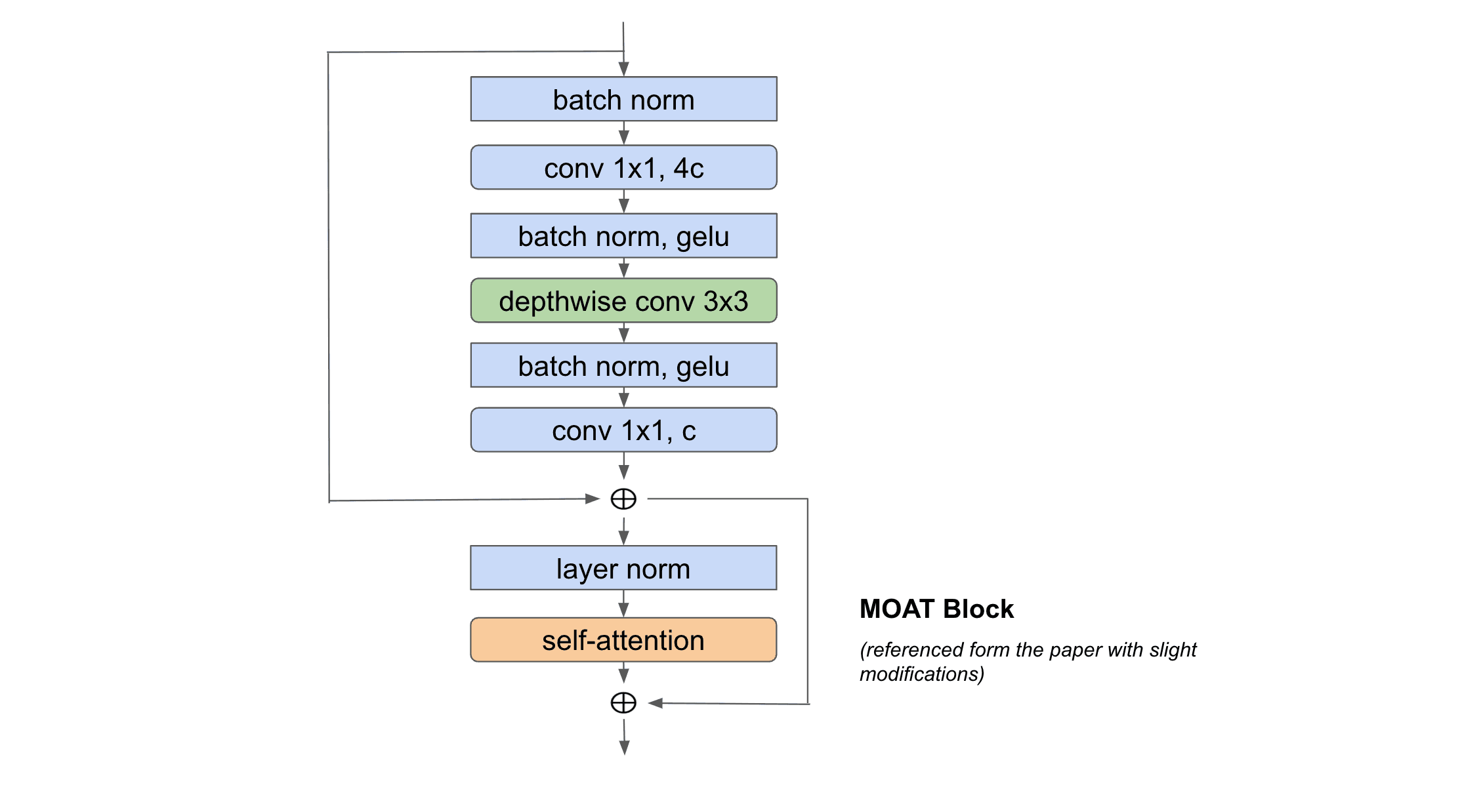
3.10. MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models

CORE IDEA (This is an Intrinsic and Extrinsic Merging Approach) [arxiv link]
This paper uses the relative attention mechanism proposed in the CoatNet paper but in addition to it, it also packages a mobile convolutional layer which together constitute the MOAT block. The design of the MOAT block is inspired by the MBConv block from MobileNet and the Transformer block. Essentially note that both the MBConv block and the Transformer block have an inverted bottleneck component and an attention component. At a high level, the MOAT block is engineered by replacing the SE attention module of the MBConv block with the self-attention from the Transformer block. In addition, the relative self-attention can be seamlessly converted to non-overlapping local relative self-attention(like SWIN Transformer), when the application requires a larger resolution for the input images. Moreover, in the case of the MOAT block, the mobile convolution within the MOAT block effectively captures any useful across-window relationships across the nonoverlapping windows from the attention stage. Thus it does not need to use a separate shifted windows mechanism and it performs better than SWIN Transformer on tasks like object detection and semantic segmentation.
MOATNet is obtained by stacking a convolutional stem, 2 stages of mobile convolutional layers followed by 2 stages of MOAT blocks. This structure was inspired by the CoAtNet and was found to be the most effective. The authors experiment with various configurations (i.e. number of blocks, number of channels within each of the 5 stages above)
INTUITION AND ADDITIONAL THOUGHTS
Alternating Convolution and Attention layers is helpful!
MOAT is essentially an extension of CoAt, the new addition is the mobile convolution layer to alternate with the attention layer. The superior performance of MOAT with just this suggestion makes intuitive sense because now the network is essentially made to alternate between focusing on global features, then focusing on local relations of these global features, then focusing on the global relations between these local relations and so on. If you think of the entire Stage as one composite operation then a stage made up exclusively of Transformer blocks and compare it to a stage made up of alternating convolution and Transformers i.e. the Transformers are broken up by convolutions in between, intuitively the stage with alternating convolutions and transformers has a stronger inductive bias, which drives the network to learn useful patterns despite the less representative power. So the stronger inductive biases help learn the optimal patterns without overfitting.
COMPUTATION AND MEMORY COST
Better than $ViTs$ (There are multiple MOAT configurations, so it can be scaled up or down as per the computational restrictions, so please refer to the paper for clear details on this)
COMPARISON
Outperforms CoAtNet and SWIN Transformer
4. Conclusion
In this article, we have seen various approaches in which the inductive biases of convolution and attention can be combined. Note that all of the results reported by the papers are on open datasets. When it comes to your research what works best might be highly dependent on your dataset, so it would be a good idea to try out multiple of these approaches.
I hope I was able to give a brief idea of these papers to you folks such that you are in a position to decide which approach(es) you want to explore further. If you have the time I highly recommend reading all the papers (I provided the arxiv links)!
If you have to choose one method I would say start with MOAT because it has the best performance compared to all the other approaches in this article and can be scaled up or down depending on the computational budget constraints