Accelerate Your Cloud-Based LLM Applications: Pro Tips for Lightning-Fast Performance 🚀
Accelerate your LLM application by 100x!

Search for a command to run...
Accelerate your LLM application by 100x!
No comments yet. Be the first to comment.
Insights into AI thinking process

LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
An overview of methods that effectively integrate their strengths
Large Language Models (LLMs) are widely used in various applications, providing significant value to users. However, developers often encounter challenges, particularly with processing times. This article explores the factors contributing to Large Language Models latency in Cloud-based LLM applications and offers tips for Enhancing LLM application speed.
We will evaluate the effectiveness of the techniques by applying them to a contextual question-answering task. We will begin with a simple baseline method and progressively enhance its speed. For the CONTEXT for LLM to answer the question, I compiled this text file [link]courtesy of the [Wikipedia Basketball] page. We will be using open source LLMs through AWS BedRock LLM hosting. Note that this setup is just an example and the ideas we discuss are generic and can be applied to any setup!
Questions: Given the following CONTEXT, the LLM will need to answer the following 20 questions (10 are unique, 10 are repeated):
questions = [
"What are the origins of basketball?",
"What is the National Basketball Association?",
"What are the different positions in basketball?",
"What are the rules of basketball?",
"What are the various violations in basketball?",
"What are the dimensions of a basketball court and the basket?",
"What is Basket Ball Association of America?",
"What is FIBA?",
"What is 'half court' variation of Basketball?",
"When and where was the first official basketball game played?"
# note that the questions are repeated again below to demonstrate
# how 'caching' can be helpful in cases where LLM is asked
# the same questions multiple times
"What are the origins of basketball?",
"What is the National Basketball Association?",
"What are the different positions in basketball?",
"What are the rules of basketball?",
"What are the various violations in basketball?",
"What are the dimensions of a basketball court and the basket?",
"What is Basket Ball Association of America?",
"What is FIBA?",
"What is 'half court' variation of Basketball?",
"When and where was the first official basketball game played?"
]
str) of length 61510.context = open("data.txt", "r").read()
len(context)
_______________________________________________________
CODE OUTPUT:
61510
from langchain_aws import ChatBedrock
from langchain_core.prompts import PromptTemplate
llm = ChatBedrock(
model_id="meta.llama3-1-405b-instruct-v1:0",
model_kwargs=dict(max_gen_len=2048,temperature=0.5,top_p=0.9),
region_name='us-west-2'
)
prompt = PromptTemplate.from_template("TASK: Your Task is to answer the 'QUESTION' below using only the information udner the 'CONTEXT' section given below. \n\
CONTEXT: \n {context} \n \
QUESTION: {question} \n \
ANSWER: ")
chain = prompt | llm
start_time = time.time()
baseline_answers={}
for ix,q in enumerate(questions):
print(ix,q)
response = chain.invoke({"question":q, "context":context})
baseline_answers[q]=response.content
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
______________________________________________________________
CODE OUTPUT:
time taken(in minutes): 6.38227390050888
We use the time.time() function to calculate how long it takes to generate all the answers for this baseline case.
As we can see x minutes it took 6.38 minutes for the baseline setup to get all the answers.
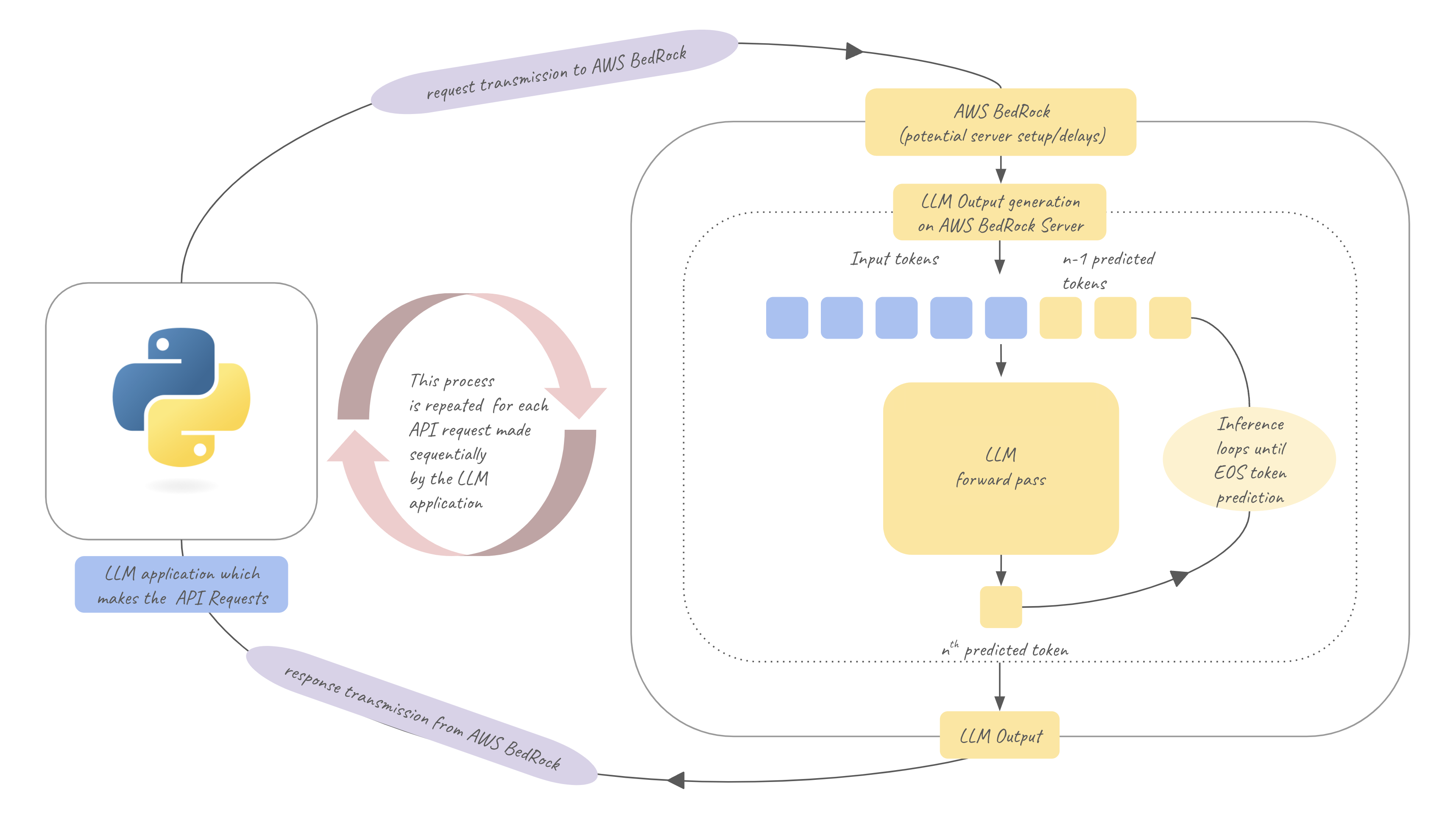
The above figure helps us understand the stages that are time-consuming:
LLM Output Generation time
LLMs generate outputs in an autoregressive manner, meaning they generate one token at a time sequentially. For generating the nth output token, this process involves running LLM forward pass over all input tokens plus the previously generated n-1 output tokens to predict a probability distribution for the nth token, then the nth token is obtained by sampling from this probability distribution. The new token is now combined with previous tokens and this process of running LLM forward pass this way is kept repeating sequentially until the model reaches a stopping condition (like generating a special "end-of-sequence" token or reaching a length limit). This is the process that this process for generating the answer for one single question/prompt. This entire process would be repeated for each question.
So the time taken for this stage chiefly depends on three factors:
How long does it take to run the token wise LLM forward pass once to generate one token?
How many times does the token wise LLM forward pass need to be run to generate the LLM output for one prompt?(i.e how many tokens are in the LLM’s generated answers?)
How many questions are we processing sequentially?
Network transmission time
Whenever an LLM API is invoked by our script the data must be transmitted over a network to AWS BedRock’s servers and once outputs are generated on BedRock they must be transmitted back to our server via a network. These round trip network transmissions take time. By itself they are usually not bad but if you make many such API requests one after the other i.e sequentially (as we are in our baseline setup) then these transmission times can quickly add up.
LLM host server delay time
Each time our request is received by BedRock(or whatever host we use) servers it may not be immediately executed, there could be delays due to Quota/Limits set by the cloud LLM host ex: not more than 200k tokens per minute per account etc. When we exceed our quota then typically the requests are kept waiting until the counter resets. This wait time depending on how often we have to wait can quickly add up. In addition there could also be other delays due to the traffic being experienced by the cloud provider or delays for any setup time on the server etc. Since this is happening on the LLM cloud host's servers there often is not a lot we can do to improve it.
We will explore different ideas to speed up our setup and for each idea we will see how it affects the above 3 times.
As discussed above, LLM cloud API providers, such as OpenAI, Anthropic, Bedrock, GCP, and Azure all have quotas/limits on the number of API calls or tokens you can use within a given timeframe (ex: OpenAI limits, BedRock limits). If you exceed that limit, your requests will be kept waiting until the counter resets. This can result in a significant amount of idle(wasted) time. This is the LLM host server delay time we talked about above and this can be reduced by talking moving to a tier with better limits if possible etc. I chose BedRock for this task as its free tier had better limits compared to others.
The length of the LLM generated output plays a key part in determining how many times the token wise LLM forward pass must be run to generate all the output tokens one at a time. The longer outputs have more tokens and hence LLM forward pass must be run a larger number of time compared to a shorter outputs as these would have fewer tokens. The fewer times we need to run the LLM forward pass step the shorter the LLM output generation time! Hence, making the LLM return as short answers as possible (without losing any important information) is a simple but very effective way to accelerate speed.
For example consider the following output from baseline:
print(baseline_answers["What are the different positions in basketball?"])
_________________________________________________________________________
CODE OUTPUT:
The five traditional positions in basketball are:
1. Point guard (often called the "1"): usually the fastest player
on the team, organizes the team's offense by controlling the
ball and making sure that it gets to the right player at the
right time.
2. Shooting guard (the "2"): creates a high volume of shots
on offense, mainly long-ranged; and guards the opponent's best
perimeter player on defense.
3. Small forward (the "3"): often primarily responsible for scoring
points via cuts to the basket and dribble penetration; on defense
seeks rebounds and steals, but sometimes plays more actively.
4. Power forward (the "4"): plays offensively often with their back
to the basket; on defense, plays under the basket (in a zone defense)
or against the opposing power forward (in man-to-man defense).
5. Center (the "5"): uses height and size to score (on offense),
to protect the basket closely (on defense), or to rebound.
While sometimes such detailed responses might be needed, based on my experience, we often do not need such verbose answers. A much shorter answer will do just as well. We can achieve this by adding this instruction to the LLM prompt.So let us go ahead and make a tiny change in our prompt by adding the text in as few words as possible and (keep answers as concise as possible) as shown below:
prompt = PromptTemplate.from_template("TASK: Your Task is to answer
the 'QUESTION' below in as few words as possible, using only the
information under the 'CONTEXT' section given below. \
\n\
CONTEXT: \n {context} \n \
QUESTION: {question} (keep answers as concise as possible)\n \
ANSWER: ")
Now let’s re run the same setup with this modified prompt to see how long this takes
start_time = time.time()
concise_answers={}
for ix,q in enumerate(questions):
response = chain.invoke({"question":q, "context":context})
concise_answers[q]=response.content
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
_______________________________________________________________
CODE OUTPUT:
time taken(in minutes): 3.59274493059
As you can see, when ensuring concise LLM outputs, it only took 3.59 minutes which is a 1.78x boost compared to the baseline setup. This is an impressive improvement considering that all we did was add a few words to our prompt. The new outputs are much more concise than before but still contain all the necessary information!
print(concise_answers["What are the different positions in basketball?"])
____________________________________________________________________
CODE OUTPUT:
Point guard, Shooting guard, Small forward, Power forward, and Center.
Note that these numbers deflated due to delays caused by throttling and hitting rate limits, which means if you compare the time taken for a individual question(instead of running through all of the questions list), the actual increase in performance will be much higher! You can check that out for yourselves! One thing to note is even without throttling delays, you won’t see a linear change in speed with output size due to an optimization called KV caching, which is out of scope for this discussion.
Making the output concise also likely reduces the cost as LLM APIs charge you based on number of input tokens and number of output tokens
We know that during the LLM output generation stage, the LLM token wise forward pass step needs to be run multiple times and this consumes a lot of time. So if we can reduce how long the token wise forward pass step takes even by small amount, then due to the multiplicative effect of repeating this step a lot of times, this small reduction in time can amount to a lot of time saved!
One of the things that determines how long it takes to run LLM forward pass once for predicting one output token time is the number of input tokens given as input to the LLM for that forward pass. Thus If the length of the input prompt is very large then the LLM has to process on a large number of tokens in each forward pass and needs to run a lot more computations during inference when compared to a shorter prompt, thus making forward pass step slower for very large prompts. So if your prompt is very long (as it is in our case, our context itself has a length: 61510) , if we can make the prompt much shorter then the inference time per token is faster and thus the over all LLM output generation time improves a lot!
If you have read the transformers paper, you might know that the self attention operation has O(n² time complexity. So if prompt 1 is 2x longer than prompt 2, then you might expect prompt 2 should take 4 times faster than prompt 1. However in practice you will see that it is not the case. This is because the LLM forward pass operations are implemented in a very efficient way(a lot of parallelization, KV caching etc)! So unless there is a big difference in the sizes of the prompts before and after you may not see a noticeable difference as it could be shadowed by the typical fluctuations in server wait time overhead etc.
But in our case since we do deal with a very large prompt (our CONTEXT itself has a length: 61510), if we can reduce the prompt size to say somewhere around length: 4000 we can expect a good boost. Currently we pass on the entire (and same) context to answer each of our questions, however each question mostly requires only a small subsection or two of the entire CONTEXT. So if we can retrieve just the relevant (and smaller) subsection from the bigger CONTEXT for each question then we can send just that subsection as the context for that question and greatly reduce the size of our prompt. Retrieval Augmented Generation (RAG) is the perfect tool for it. So we modify the code as show below to use a RAG setup and rerun the question answering loop as shown below. Since the chunk size is 2000 and the retriever is configured to retrieve 2 most relevant chunks, the entire prompt size will be around length:4000.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_aws import BedrockEmbeddings
from langchain.vectorstores import Chroma
from langchain_aws import ChatBedrock
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# embedding model
embeddings_model = BedrockEmbeddings(
model_id="cohere.embed-multilingual-v3",
region_name="us-west-2"
)
# text splitter
context = open("data.txt", "r").read()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=400,
length_function=len,
is_separator_regex=False,
)
# get the llm
llm = ChatBedrock(
model_id="meta.llama3-1-405b-instruct-v1:0",
model_kwargs=dict(max_gen_len=2048,temperature=0.5,top_p=0.9),
region_name='us-west-2'
)
# prompts
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question in as few words as possible and keep the "
"answer within 3 lines."
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
start_time = time.time()
# build the rag chain
text_chunks = text_splitter.split_text(context)
vector_db= Chroma.from_texts(texts=text_chunks, embedding=embeddings_model)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(vector_db.as_retriever(search_kwargs={"k": 2}), question_answer_chain)
# loop over questions
short_input_answers={}
for ix,q in enumerate(questions):
response = rag_chain.invoke({"input": q})
short_input_answers[q]=response["answer"]
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
______________________________________________________________________
CODE OUTPUT:
time taken(in minutes): 1.8067506194114684
As you can see by keeping input and output concise the time taken is only 1.81 minutes (including the time spent for additional RAG setup like getting the embedding vectors etc), which is a 3.52x boost in speed compared to the baseline setup. To inspect if the quality of output is maintained you can see an example output below:
print(short_input_answers["What are the different positions in basketball?"])
______________________________________________________________________
CODE OUTPUT:
The five positions in basketball are:
1. Point guard
2. Shooting guard
3. Small forward
4. Power forward
5. Center
Making the input concise can also reduce the cost as LLM APIs charge you based on number of input tokens and number of output tokens. However if you are using RAG - keep in mind that we need a DB to store the embedding vectors, this will increase the space requirements. In our example we used the lightweight Chroma DB, if it is not sufficient for you then depending on the size of context and how long you want to store these vectors you might need a bigger DB which might cost money
One more factor that significantly determines how long it takes to run LLM forward pass once for predicting one output token time is the size of the LLM itself! LLMs come in different sizes, some of them have just a few million parameters while others have hundreds of billions of parameters. Typically the larger an LLM the better its performance at more complex tasks, but their forward pass step is also much slower. So when choosing which LLM to use it is important that we find the sweet spot for the size and performance of the LLM for our given task. Typically you would need to run a comparison between various LLMs and choose the smallest LLM that performs at the desired level for your task.
In our case to demonstrate the impact using smaller LLM models on the overall speed, we will use the same RAG setup from tip 3 but this time we will use Llama-3.1-8Billion which is a much smaller model instead of Llama-3.1-405Billion. Since our questions are straight forward, Llama-3.1-8Billion should be good enough for our purpose.
llm = ChatBedrock(
model_id="meta.llama3-1-8b-instruct-v1:0",
model_kwargs=dict(max_gen_len=2048,temperature=0.5,top_p=0.9),
region_name='us-west-2'
)
start_time = time.time()
# build the rag chain
text_chunks = text_splitter.split_text(context)
vector_db= Chroma.from_texts(texts=text_chunks, embedding=embeddings_model)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(vector_db.as_retriever(search_kwargs={"k": 2}), question_answer_chain)
# loop over questions
smaller_llm_answers={}
for ix,q in enumerate(questions):
response = rag_chain.invoke({"input": q})
smaller_llm_answers[q]=response["answer"]
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
______________________________________________________________
CODE OUTPUT:
time taken(in minutes): 0.33349846601486205
As you can when using a smaller LLM and keeping the input and output concise the time taken this time is only 0.33 minutes, which is a 19.33x boost in speed compared to the baseline setup.
Note that as we are using a smaller LLM we must also make sure to inspect the answers to ensure that the smaller LLM doesn't deteriorate performance, we can see an example answer below.
print(smaller_llm_answers["What are the different positions in basketball?"])
______________________________________________________________
CODE OUTPUT:
There are 5 main positions in basketball:
1. Point Guard (1)
2. Shooting Guard (2)
3. Small Forward (3)
4. Power Forward (4)
5. Center (5)
As we can see Llama-3.1-8-Billion does a good job for our questions and is good enough for us. In your case if you some of your questions are complex and some are easy then you can consider using smaller LLMs for the easier questions and bigger ones for the more complex ones. It will be a little more code to write and maintain but would be much faster!
Note that one of the reasons why even a smaller model is able to do just as good a job as a larger model in our case is because we are using RAG and instead of sending a large context we only send a short and very relevant context to the LLM which makes it much easier even for a smaller LLM to understand and answer appropriately. I often notice in my experimentation that if I do not use RAG then using a smaller LLM can often deteriorate performance.
Using a smaller LLM would also likely reduce the cost as LLM APIs charge you based on model size.
In our case we have 20 total questions but only 10 unique questions as each question is repeated twice. Such a situation is often encountered(ex: your chat bot might be posed the exact question “Which city is the Statue of Liberty located?“, by multiple users). Each time we make a request to the LLM API, we have to incur the LLM output generation time, network transmission time and also any potential LLM host server delay time. So we should make the LLM API request for a question only if it is necessary. In cases when we anticipate to have duplicate questions, whenever an LLM API request is made, we can cache the (question, corresponding LLM response) in a local cache, then the next time our application need’s to answer a duplicate question, we will find this question already in the cache and can return the corresponding answer from the cache instead of making an LLM API request.
How long do you want this cache to persist, how similar can the questions be to be still considered same etc will determine the LLM caching techniques to use (ex: semantic caching). In our case our repeated questions are exact duplicates so for the purpose of demonstrating the effect of caching we will just use a simple InMemoryCache from LangChain (you can even use a dictionary and store (prompt, answers) as key value pairs to make a basic cache but using LangChain’s InMemoryCache takes care of the bookkeeping for us so its much simpler).
from langchain.globals import set_llm_cache
from langchain_community.cache import InMemoryCache
set_llm_cache(InMemoryCache())
start_time = time.time()
# build the rag chain
text_chunks = text_splitter.split_text(context)
# vector_db= Chroma.from_texts(texts=text_chunks, embedding=embeddings_model)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(vector_db.as_retriever(search_kwargs={"k": 2}), question_answer_chain)
# loop over questions
caching_input_answers={}
for ix,q in enumerate(questions):
response = rag_chain.invoke({"input": q})
caching_input_answers[q]=response["answer"]
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
______________________________________________________________
CODE OUTPUT:
time taken(in minutes): 0.1818416714668274
The previous setup was using a small LLM and concise inputs and outputs and took 0.33 minutes , and now after adding caching on top of the same setup we only take 0.18 minutes i.e is around half the time, this makes sense because we now only make 10 LLM API calls instead of 20 like before. Overall we have a 35.44x boost in speed compared to the baseline setup.
Using caching would also likely reduce the cost as we use the LLM APIs fewer times.
When we sequentially execute the LLM API requests while each request is being processed by the API, the execution is just idling at that line of code and is resumed only after we get the return response from LLM API. This is an i/o bound latency and a perfect fit for concurrent execution using Multithreading, Async IO, Batch Processing etc.
To illustrate this we will use the same setup as before(i.e concise inputs, concise outputs, small LLM, caching enabled) and run the same exact computations but now we will run it in parallel for each question by adding multithreading. Note that since our example task is a toy application it is a bit tricky to reap the benefits of multi threading and caching at the same time, for example if we use 20 threads and processing for all 20 questions begins at once then since the cache is empty at this point all 20 requests would be sent to LLM API even though only 10 would be sufficient and we would not be benefitting from cache, so I put number of threads as 10 in hopes to get benefits from both. But in more complex real world scale of the number of requests this won’t be an issue! The code with multithreading is shown below:
from concurrent.futures import ThreadPoolExecutor
from langchain.globals import set_llm_cache
from langchain_community.cache import InMemoryCache
set_llm_cache(InMemoryCache())
start_time = time.time()
# build the rag chain
text_chunks = text_splitter.split_text(context)
# vector_db= Chroma.from_texts(texts=text_chunks, embedding=embeddings_model)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(vector_db.as_retriever(search_kwargs={"k": 2}), question_answer_chain)
def rag_chain_func(q):
response = rag_chain.invoke({"input": q})
return q,response["answer"]
# loop over questions
with ThreadPoolExecutor(max_workers=10) as exe:
exe.submit(rag_chain_func,2)
# Maps the method 'cube' with a list of values.
result = exe.map(rag_chain_func,questions)
parallelized_answers={q:a for (q,a) in result}
end_time = time.time()
print(f"time taken(in minutes): {(end_time-start_time)/60}")
______________________________________________________________
CODE OUTPUT:
time taken(in minutes): 0.06619486411412558
As you can when using multithreading (i.e concise inputs, concise outputs, small LLM, caching enabled) the time taken this time is only 0.07 minutes, which is a 91.14x boost 🚀 in speed compared to baseline setup!
The application is making the same amount of API calls as before and thus require s the same overall LLM out generation time, network transmission time, potential LLM host server delay time etc for each question, so even though each question takes the same time as before since we are processing all of the questions in parallel we increase the throughput of the application tremendously!
Multithreading vs Batch inference
Another option to parallelize the processing is to use batch inference for LLMs, in this approach instead of asking one question per request, a batch of questions is sent in one single LLM API request and these questions are processed on GPU in parallel by the LLM. While using batch inference since we only make one request(assuming that in our case batch size is 10 and we are using caching) the avg. network transmission times and avg. LLM host server delay times are all vastly reduced per question i.e network transmission optimization. The avg. LLM output generation time is also reduced because all the answers are generated in parallel.
Note that for this to work the underlying LLM API must support batch inference. In our case we are using AWS BedRock API’s through LangChain and LangChain does not have this support for BedRock API’s. So I will not demonstrate that but the code changes required are minimal you just need to call the batch method instead of invoke. Refer to this LangChain documentation for examples.
Sometimes the API pricing for batch inference is cheaper than single input inference, so if supported, then using batch inference might save time and money both! You can of course combine both multithreading and batch inference as well!
All the data I used can be found here: [Github link]
This article explored techniques to accelerate cloud-based LLM applications. Starting with a baseline setup, we identified key time-consuming steps such as LLM output generation, network transmission, and host server delays. By implementing tips like making inputs and outputs concise, using smaller LLMs, caching, and parallelization, we achieved a significant LLM application acceleration of 91.14x 🚀 in processing speed. These optimizations enhance performance and can reduce costs, enabling developers to create more efficient and responsive LLM applications for a better user experience.
Blogs that talk about LLM latency
Microsoft: The LLM Latency Guidebook: Optimizing Response Times for GenAI Applications
ChatGPT isa good resource as well